23 KiB
🇬🇧 English version | 🇷🇺 Русская версия
Atomic Threat Coverage
Automatycznie generowana analityczna baza wiedzy zaprojektowana, aby zwalczać zagrożenia na podstawie MITRE ATT&CK.
![]()
Atomic Threat Coverage jest narzędziem, które pozwala na automatyczne generowanie analitycznej bazy wiedzy zaprojektowanej, aby zwalczać zagrożenia (na podstawie modelu "przeciwnika" przygotowanego przez MITRE ATT&CK) poprzez Detekcje, Reakcje, Przeciwdziałanie oraz Symulacje:
- Detection Rules — Reguły Wykrywania w oparciu o Sigme — Generic Signature Format for SIEM Systems
- Data Needed — Wymagane Dane w celu odtworzenia konkretnego Zagrożenia
- Logging Policies — Polityki Logowania jakie muszą być skonfigurowane na urządzeniach wysyłające logi, aby móc zbierać Wymagane Dane
- Enrichments — Wzbogacenia dla konkretnych Wymaganych Danych, które wymagane są dla niektórych Reguł Wykrywania
- Triggers — Wyzwalacze na podstawie Atomic Red Team — testy wykrywające Zagrożenie na podstawie MITRE ATT&CK
- Response Actions — Akcje, które zostają wykonane podczas incydent bezpieczeństwa
- Response Playbooks — Playbooki Reakcyjne, aby reagować, gdy Reguła Wyzwalania zostanie wyzwolona przez konkretne Zagrożenie
- Hardening Policies — Polityki Hardeningu, które muszą zostać zaimplementowane, aby przeciwdziałać konkretnemu Zagrożeniu
- Mitigation Systems — Systemy do Przeciwdziałania, które muszą zostać wdrożone, aby przeciwdziałać konkretnemu Zagrożeniu
Atomic Threat Coverage jest wysoko zautomatyzowanym frameworkiem służącym do gromadzenia, rozwijania, wyjaśniania oraz dzielenia się odpowiednią analizą.
Opis
Motywacja
Istnieje wiele projektów, które dostarczają analizy (lub funkcjonalność) skupiającą się na konkretnych zagadnieniach (Sigma, Atomic Red Team, MITRE CAR). Wszystkie z nich posiadają jedną słabość - istnieją we własnej przestrzeni. W rzeczywistości wszystko jest ściśle powiązane - dane do alertów nie biorą się znikąd, wygnerowane alerty nie idą w próżnię. Każda funkcja, jak dla przykładu zbieranie danych, administracja systemów, detekcji zagrożeń, reakcji na incydent itp są częścią kompleksowego procesu implementowanego przez wiele działów oraz wymagającego ich ścisłej współpracy.
Zdarza się, że problemy jednej funkcji mogą być w tańszy, prostszy i bardziej efektywny sposób rozwiązane przy pomocy metod stosowanych dla innej funkcji. Większość zadań nie może być rozwiązanych jedynie przy pomocy wyłącznie jednej funkcji. Każda z funkcji opiera się na możliwościach oraz jakości drugiej. Nie jest możliwa efektywna detekcja zagrożeń bez poprawnej kolekcji danych i wzbogacania ich. Nie możliwa jest także prawidłowa odpowiedź na zagrożenia bez zrozumienia, których technologii/systemów/środków można użyć do zablokowania konkretnego zagrożenia. Przeprowadzanie testów penetracyjnych lub ćwiczeń Red Team nie przynosi korzyści, jeśli nieznane są możliwości procesów, personelu i systemów do blokowania, wykrywania oraz reagowania na incydenty. Wszystko to wymaga bliskiej interakcji i zrozumienia między działami.
W praktyce problemy w kolaboracji wynikają z:
- Braku wspólnego modelu/klasyfikacji zagrożenia, wspólnej terminologii oraz języka do opisu zagrożeń
- Braku jednomyślnego pojmowania celu
- Braku prostego wyjaśnienia konkretnych wymogów
- Różnicy w kompetencjach
Dlatego zdecydowaliśmy się stworzyć Atomic Threat Coverage - projekt mający na celu połączenie różnych funkcji w ramach jednej metodologii (Lockheed Martin Intelligence Driven Defense® lub MITRE Threat-based Security), modelu zagrożenia (MITRE ATT&CK) oraz dostarczenie efektywnego narzędzia do kolaboracji nad wspólnym wyzwaniem - zwalczaniem zagrożeń.
Dlaczego Atomic Threat Coverage
Praca z wieloma [1][2][3][4] repozytoriami analizy/detekcji często przypomina niekończącą się procedurę kopiuj/wklej, manualną adaptację informacji do formatu wewnętrzej bazy wiedzy, modeli detekcji czy mapowania na wewnętrzne metryki.
Postanowiliśmy zrobić to inaczej.
Atomic Threat Coverage jest narzędziem, które pozwala na stworzenie i utrzymywania własnego repozytorium analitycznego, importowanie danych z innych projektów (przykładowo Sigma, Atomic Red Team jak również z prywantej kopii tych projektów z własnymi analizami, oraz wyeksportowanie wszystkich informacje do czytelnego dla człowieka formatu, w stylu wiki, na dwa (jak dotąd) sposoby:
- Atlassian Confluence (tutaj znajduje się demo bazy wiedzy automatycznie wygenerowanej przez Atomic Threat Coverage)
- To repozytorium samo w sobie — wiki stworzona przy użyciu plików markdown
Innymi słowy, nie potrzeba już samodzielenie pracować nad warstwą prezentacji manualnie. Wystarczy skupić się na wartościowej pracy (np. tworzenie reguł Sigma), a Atomic Threat Coverage automatycznie wygeneruje analityczną bazę danych ze wszystkimi danymi, mapując wszystkie wartościowe metryki. Gotowe do użycia, udostępniania i prezentowania kierownictwu, klientowi i kolegom repozytorium.
Zasada działania
Wszystko zaczyna się od reguł Sigma, a kończy na czytelnym dla człowieka formacie w stylu wiki. Atomic Threat Coverage parsuje regułe oraz:
- Mapuje Regułe Wykrywania do taktyki i techniki ATT&CK używając
tagsz reguły Sigma - Mapuje Regułe Wykrywania do Wymaganych Danych używając
logsourcei sekcjidetectionz reguły Sigma - Mapuje Regułe Wykrywania do Wyzwalania (testy od Atomic Read Team) używając
tagsz reguły Sigma - Mapuje Regułe Wykrywania do Wzbogacenia używając istniejącego już mapowania wewnątrz Reguły Wykrywania
- Mapuje Playbooki Reakcyjne do taktyki i techniki ATT&CK używając istniejącego już mapowania wewnątrz Reguły Wykrywania
- Mapuje Playbooki Reakcyjne do Akcji używając istniejącego już mapowania wewnątrz Reguły Wykrywania
- Mapuje Politykę Logowania do Wymaganych Danych używając istniejącej już mapy w Wymaganych Danych
- Za pomocą szablonów jinja (
scripts/templates) konwertuje wszystko w strony Confluence oraz pliki Markdown - Zapisuje wszystkie pliki do lokalnego repozytorium oraz na serwer Confluence (w zależności od konfiguracji w
scripts/config.py) - Tworzy pliki
analytics.csvorazpivoting.csvdo prostej analizy istniejących danych - Tworzy plik
atc_export.json- profil ATT&CK Navigator do wizualizacji aktualnie zdolności wykrywania zagrożeń
Od zaplecza
Dane w repozytorium:
├── analytics.csv
├── pivoting.csv
├── data_needed
│ ├── DN_0001_4688_windows_process_creation.yml
│ ├── DN_0002_4688_windows_process_creation_with_commandline.yml
│ └── dataneeded.yml.template
├── detection_rules
│ └── sigma/
├── enrichments
│ ├── EN_0001_cache_sysmon_event_id_1_info.yml
│ ├── EN_0002_enrich_sysmon_event_id_1_with_parent_info.yaml
│ └── enrichment.yml.template
├── logging_policies
│ ├── LP_0001_windows_audit_process_creation.yml
│ ├── LP_0002_windows_audit_process_creation_with_commandline.yml
│ └── loggingpolicy_template.yml
├── response_actions
│ ├── RA_0001_identification_get_original_email.yml
│ ├── RA_0002_identification_extract_observables_from_email.yml
│ └── respose_action.yml.template
├── response_playbooks
│ ├── RP_0001_phishing_email.yml
│ ├── RP_0002_generic_response_playbook_for_postexploitation_activities.yml
│ └── respose_playbook.yml.template
└── triggering
└── atomic-red-team/
Detection Rules
Detection Rules — Reguły Wykrywania są niezmodyfikowanymi regułami Sigma. Domyślnie Atomic Threat Coverage używa reguł z oficjalnego repozytorium aczkolwiek nic nie stoi na przeszkodzie, aby dołożyć reguły z własnego rezpotyrium.
Plik yaml Detection Rule (kliknij aby rozwinąć)

Strona confluence stworzona w pełni automatycznie (kliknij aby rozwinąć)

Strona markdown (Gitlab) stworzona w pełni automatycznie (kliknij aby rozwinąć)

Linki do Wymaganych Danych, Wyzwalaczy oraz artykułów na stronie ATT&CK są generowane automatycznie.
Reguła Sigma, zapytanie dla Kibany, X-Pack Watcher oraz GrayLog są generowane oraz dodawane automatycznie (istnieje możliwość rozszerzenia generowanych zapytań na podstawie wspieranych przez projekt Sigma platform Sigma Supported Targets )
Data Needed
Plik yaml Data Needed (kliknij aby rozwinąć)

Automatycznie wygenerowana strona confluence (kliknij aby rozwinąć)

Automatycznie wygenerowana strona markdown (kliknij aby rozwinąć)

Ten moduł ma na celu ułatwienie komunikacji z zespołami SIEM/LM/Data Engineering. Zawiera następujęce dane:
- Przykładowy czysty log aby opisać jakich danych należy się spodziewać lub zbierać
- Opis danych do zebrania (Platform/Type/Channel/etc) - wymagany do wyznaczenia mapowania Polityk Logowania
- Listę pól wymaganą do wyznaczenia mapowania Reguł Wykrywania, Playbooki Reakcyjnych oraz wygenerowania pliku
analytics.csv
Logging Policies
Plik yaml Polityki Logowania (kliknij aby rozwinąć)

Automatycznie wygenerowana strona confluence (kliknij aby rozwinąć)

Automatycznie wygenerowana strona markdown (kliknij aby rozwinąć)
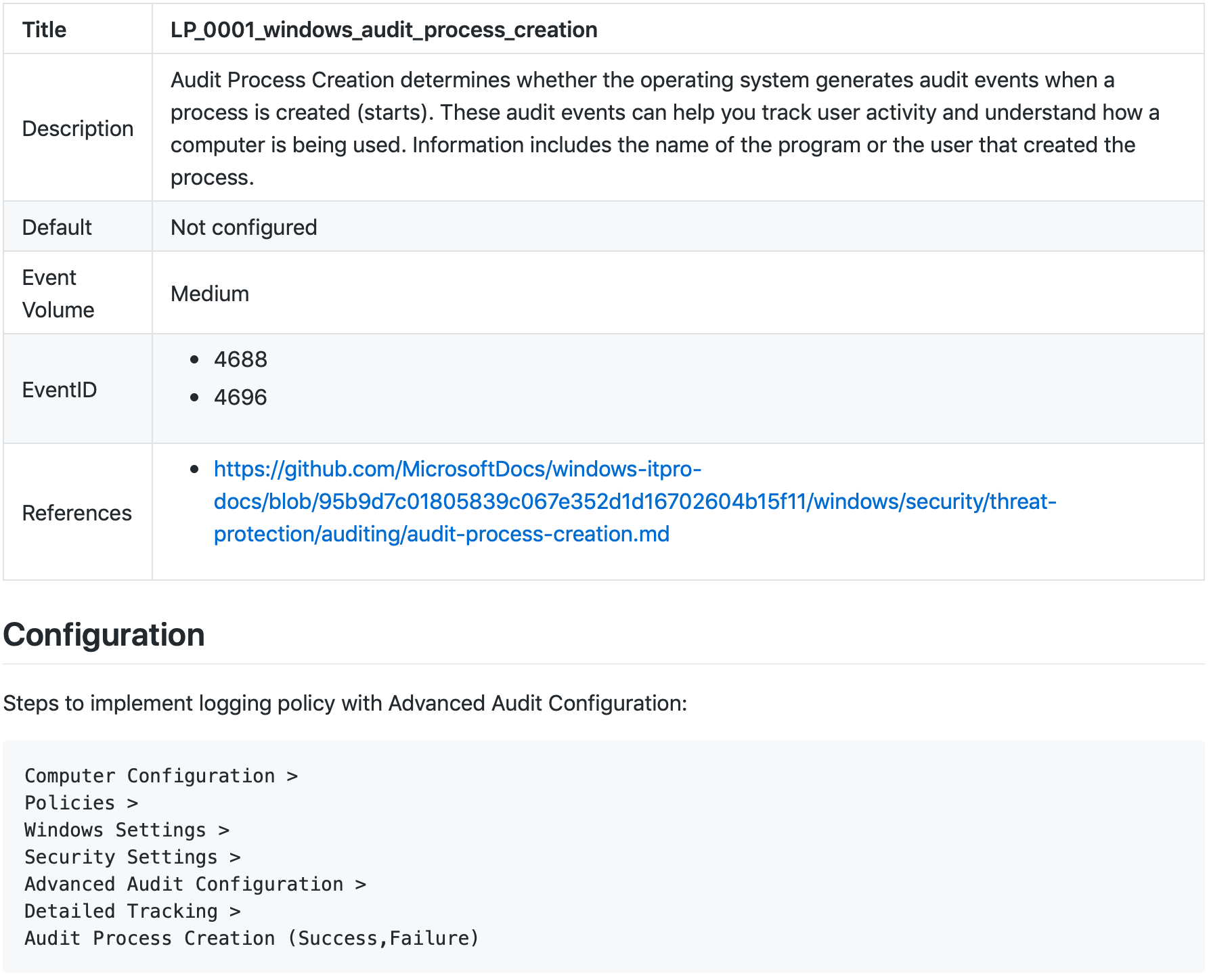
Ten moduł ma na celu wyjaśnienie zespołom SIEM/LM/Data Engineering, lub ogólnie działom IT jakie polityki logowania muszą być skonfigurowane, aby odpowiednie dane (Wymagane Dane) były wysyłane w celu poprawnego działania Reguł Wykrywania by wykryć konkretne Zagrożenia. Dodatkowo zawarto w nim instrukcje jak krok po kroku należy takie polityki skonfigurować.
Enrichments
Plik Wzbogaceń (kliknij aby rozwinąć)

Automatycznie wygenerowana strona confluence (kliknij aby rozwinąć)

Automatycznie wygenerowana strona markdown (kliknij aby rozwinąć)

Ten moduł ma za zadanie uprościć komunikacje z zespołami SIEM/LM/Data Engineering lub ogólnie z działami IT. Zawiera następujące informacje:
- Lista Wymaganych Danych, które mogłby by być "wzbogacone"
- Opis Wzbogacenia (nowe pola, tłumaczenie/zmiana nazw pól, rozwiązywanie nazw DNS, itd)
- Przykład implementacji (na przykład, konfiguracja Logstash)
W ten sposób będzie można w prosty sposób wyjaśnić dlaczego wzbogacenie (logów/danych) jest potrzebne (mapowanie do Reguł Wykrywania) jak i wskazanie konkretnych platform do wzbogacania danych (na przykład Logstash).
Triggers
Wyzwalacze to niezmodyfikowane testy Atomic Red Team. Domyślnie Atomic Threat Coverage używa "atomics" z oficjalnego repozytorium, ale nic nie stoi na przeszkodzie by dodać "atomics" z własnego repozytorium.
Plik yaml Wyzwalacza (kliknij aby rozwinąć)

Automatycznie wygenerowana strona confluence (kliknij aby rozwinąć)

Automatycznie wygenerowana strona markdown (kliknij aby rozwinąć)

Ten moduł pozwala na techniczne przetestowanie systemu. Szczegółowy opis można znaleźć na oficjalnej stronie.
Response Actions
Plik yaml Akcji (kliknij aby rozwinąć)

Automatycznie wygenerowana strona confluence (kliknij aby rozwinąć)
Automatycznie wygenerowana strona markdown (kliknij aby rozwinąć)
Ten moduł używany jest do budowania Playbooków Reakcyjnych
Response Playbooks
Plik yaml Playbooka Reakcyjnego (kliknij aby rozwinąć)

Automatycznie wygenerowana strona confluence (kliknij aby rozwinąć)
Automatycznie wygenerowana strona markdown (kliknij aby rozwinąć)
Ten moduł używany jest jako plan reakcji na incydent bezpieczeństwa dla konkretnego zagrożenia.
analytics.csv
Atomic Threat Coverage generuje plik analytics.csv z listą wszystkich zmapowanych danych do filtrowania i prostej analizy. Ten plik powinien odpowiedzień na następujące pytania:
- W jakich zródłach danych można znaleźć konkrente typy danych (przykładowo nazwa domeny, nazwa użytkownika, hash etc.) podczas fazy identyfikacji?
- Które Polityki Logowania potrzebuję wdrożyć, aby zbierać dane do wykrywania konkretnego zagrożenia?
- Które Polityki Logowania mogę wdrożyć wszędzie, a które tylko na urządzeniach "krytycznych"?
- Które dane pozwalają mi na alarmy high-fidelity? (Priorytetyzacja wdrażania polityk logowania, itd.)
- itd
Takie mapowanie powinno pomóc organizacji priorytetyzować wykrywanie zagrożeń w przełożeniu na pieniądze, np:
- Jeśli zbieramy wszystkie Wymagane Dane ze wszystkich urządzen dla wszystkich Reguł Wykrywania, oznacza to X EPS (Events Per Second) z określonymi środkami na magazynowanie danych i ich procesowanie.
- Jeśli zbieramy Wymagane Dane tylko dla alarmów high-fidelity i tylko na "krytycznych" urządzeniach, oznacza to Y EPS (Events Per Second) z określonymi środkami na magazynowanie danych i ich procesowanie
- itd
pivoting.csv
Atomic Threat Coverage generuje plik pivoting.csv z listą wszystkich pól (z Wymaganych Danych) zmapowane do opisu Wymaganych Danych dla konkretnego zastosowania - dostarcza to informacje na temat urządzeń końcowych, gdzie można znaleźć jakieś konkretne dane, na przykład nazwa domenowa, nazwa użytkownika, hash, itd.
Nasze cele
- Zachęcenie społeczności do używania formatu plików Sigma (więcej osób wnoszących wkład, więcej i lepsze konwertery)
- Zachęcenie społeczności do używania formatu testów Atomic Red Team (więcej osób wnoszących wkład - więcej testów)
- Promować dzielenie się informacją na temat zagrożeń
- Zautomatyzować większość ręcznej pracy
- Dostarczenie społeczności bezpieczeństwa informacji framework, który poprawi komunikacje z innymi działami, ogólną analizę, dewelopowanie i udostępnianie workflow'u
Workflow
- Dodaj swoje własne reguły Sigma (jeśli posiadasz) do folderu
detectionrules - Dodac folder z własnymi testami Atomic Red Team (jeśli posiadasz) do folderu
triggering - Dodaj odpowiednie Wymagane Dane związane z regułami Sigma do folderu
dataneeded(szablon do tworzenia nowych dostępny jest w tutaj) - Dodaj odpowiednie Polityki Logowania związane z Wymaganymi Danymi do folderu
loggingpolicies(szablon do tworzenia nowych dostępny jest tutaj) - Dodaj odpowiednie Wzbogacenia do folderu
enrichments(szablon do tworzenia nowych dostępny jest tutaj) - Dodaj odpowiednie Akcje do folderu
response_actions(szablon do tworzenia nowych dostępny jest tutaj) - Dodaje odpowiednie Playbooki Reakcyjne do folderu
response_playbooks(szablon do tworzenia nowych dostępny jest tutaj) - Skonfiguruj ustawienia eksportowania (markdown/confluence) -
scripts/config.py - Wykonaj polecenie
makew głównym katalogu repozytorium
Aktualny status: Alfa
Projekt aktualnie jest w fazie Alfa. Nie wspiera wszystkich istniejących reguł Sigma (aktualne pokrycie to ~80%). Są też inne moduły, które muszą zostać wydewelopowane (na przykład Systemy do Przeciwdziałania). Ciepło przyjmujemy jakikolwiek feedback i sugestie w celu udoskonalenia projektu.
Wymagania
- Unix OS lub Windows Subsystem for Linux (WSL) (wymagane do wykonania polecenia
make) - Python 3.7.1
- Biblioteka python - jinja2
- (Darmowy) Plugin do Confluence'a - Render Markdown (open-source)
FAQ
Czy moje prywatne reguły (Reguły Wykrywania, Polityki Logowania, itd) są gdzieś wysyłane?
Nie. Jedynie do instancji confluence, która została wskazana w pliku konfiguracyjnym scripts/config.py. Atomic Threat Coverage nie łączy się do żadnego innego zdalnego urządzenia. Jest to łatwo weryfikowalne - kod w całości udostępniony.
Co macie na myśli pisząc "promować dzielenie się informacją na temat zagrożeń"?
Chcemy, żeby używane były formaty promowane przez społeczeństwo dla (przynajmniej) Reguł Wykrywania (Sigma) oraz Wyzwalaczy (Atomic Red Team). W przyszłości mamy nadzieje, że użytkownicy będą skłonni i chętni, aby podzielić się ze społeczeństwem ciekawymi informacjami na temat zagrożeń. Natomiast zero presji, to tylko i wyłącznie Twoja decyzja.
Jak mogę dodać nowy Wyzwalacz, Regułę Wykrywania lub czegokolwiek do mojego prywatnego repozytorium Atomic Threat Coverage?
Najprościej jest podążać krokami zdefiniowanymi w workflow. Po prostu dodaj swoje reguły do już skonfigurowanych folderów dla danego typu informacji.
Bardziej "produkcyjnym" podejściem jest skonfigurowanie prywatnych repozytoriów Sigma i Atomic Red Team jako projektów submodules prywatnego repozytorium Atomic Threat Coverage. Po zrobieniu tego pozostaje jedynie skonfigurowanie odpowiednio ścieżek do nich w scripts/config.py. Po skonfigurowaniu, Atomic Threat Coverage zacznie korzystać z nich do tworzenia bazy wiedzy.
Sigma nie wspiera paru moich Reguł Wykrywania. Czy używać w takim razie Atomic Threat Coverage?
Oczywiście. My również mamy pare Reguł Wykrywania, które nie są automatycznie konwertowane przez Sigma do zapytań SIEM/LM. Dalej używamy formatu Sigma dla takich Reguł używając niewspieranej logiki detekcji w sekcji "condition". Następnie zespoły SIEM/LM manulanie tworzą reguły bazując na opisie tego pola. Atomic Threat Coverage to nie tylko automatyczne generowania zapytań oraz dokumentacji, Atomic Threat Coverage dalej przynosi parę pozytywów dla analizy, których nie dałoby się wykorzystać z regułami w innym formacie niż Sigma.
Autorzy
- Daniil Yugoslavskiy, @yugoslavskiy
- Jakob Weinzettl, @mrblacyk
- Mateusz Wydra, @sn0w0tter
- Mikhail Aksenov, @AverageS
Podziękowania
- Igor Ivanov, @lctrcl za współpracę nad początkowymi typami danych oraz regułami mapowania
- Andrey, Polar_Letters za logo
- Sigma, Atomic Red Team, TheHive oraz Elastic Common Schema za inspitacje do stworzenia tego projektu
- MITRE ATT&CK za umożliwienie stworzenia tego wszystkiego
TODO
- Wydewelopowanie generowania szablonów TheHive Case bazując na Playbookach Reakcyjnych
- Wydewelopowanie kontenera docker dla tego narzędzia
- Implementacja modułu "Mitigation Systems"
- Implementacja modułu "Hardening Policies"
- Implementacja jednolitego Modelu Danych (nazwy pól)
- Implementacja nowego modułu - "Visualisation" jako pliki yaml z wizaulizacją/dashboardami Kibana z możliwością przekonwertowania do komend curl w celu wrzucenia ich do Elasticsearch
Linki
[1] MITRE Cyber Analytics Repository
[2] Endgame EQL Analytics Library
[3] Palantir Alerting and Detection Strategy Framework
[4] The ThreatHunting Project
Licencja
Dostępna w pliku LICENSE.