48 KiB
🇬🇧 English version | 🇵🇱 Polska wersja
Atomic Threat Coverage
Автоматически генерируемая действенная аналитика, предназначенная для противодействия угрозам, описанным в MITRE ATT&CK.
![]()
Atomic Threat Coverage это утилита которая позволяет автоматически сгенерировать действенную аналитику, предназначенную для противодействия угрозам, описанным в MITRE ATT&CK с позиций Обнаружения, Реагирования, Предотвращения и Имитации угроз:
- Detection Rules — Правила Обнаружения основанные на Sigma — общем формате описания правил корреляции для SIEM систем
- Data Needed — данные, которые необходимо собирать для обнаружения конкретной угрозы
- Logging Policies — настройки логирования, которые необходимо произвести на устройстве для сбора данных, необходимых для обнаружения конкретной угрозы
- Enrichments — настройки обогащения данных (Data Needed) необходимые для реализации некоторых Правил Обнаружения (Detection Rules)
- Triggers — сценарии имитации атак основанные на Atomic Red Team — атомарных тестах/сценариях реализации угроз из MITRE ATT&CK
- Response Actions — атомарные шаги реагирования на инциденты
- Response Playbooks — сценарии реагирования на инциденты, сгенерированные в ходе обнаружения конкретной угрозы, составленные на основе Response Actions
- Visualisations - визуализации для создания дашборд Threat Hunting / Triage
- Hardening Policies — настройки систем, которые позволяют нивелировать конкретную угрозу
- Mitigation Systems — системы и технологии, которые позволяют нивелировать конкретную угрозу
- Customers — заказчики аналитики, которые могут быть как внешними, так и внутренними. Эта сущность необходима для отслеживания статусов реализации
Atomic Threat Coverage является автоматизированным фреймворком для сохранения, разработки, анализа и распространения практической, действенной аналитики.
Описание
Предпосылки
Существует много достойных проектов, которые реализуют функциональность (или предоставляют аналитику) конкретной направленности (Sigma — Обнаружение, Atomic Red Team — Имитация угроз). Их объединяет один недостаток — они существуют в вакууме своей области. В реальности же все очень тесно взаимосвязанно — данные для обнаружения угроз не берутся из ниоткуда, и генерируемые Алерты не уходят в никуда. Сбор данных, администрирование систем защиты, обнаружение угроз или реагирование на них — это составная часть большого и сложного процесса, требующего плотного взаимодействия нескольких подразделений.
Проблемы одной функции зачастую проще, дешевле и эффективнее решать методами другой. Многие задачи не решаются в рамках одной функции. Каждая из функций базируется на возможностях и качестве другой. Не получится эффективно детектировать угрозы и реагировать на инциденты без сбора и обогащения необходимых данных. Не получится эффективно реагировать на инциденты без понимания того, какими средствами/системами/технологиями можно блокировать угрозу. Крайне неэффективно проводить тестирование на проникновение или Red Team exercises без представления о возможностях процессов, персонала и систем по блокированию, обнаружению и реагированию на инциденты. Все это требует тесного взаимодействия и взаимопонимания между подразделениями.
На практике наблюдается сложность во взаимодействии, обусловленная следующими факторами:
- Отсутствие общей модели/классификации угроз, общей терминологии
- Отсутствие понимания общих целей
- Отсутствие простого метода выражения своих потребностей
- Разница в компетенциях (как в плане глубины, так и в плане различия предметных областей)
Именно поэтому мы решили разработать Atomic Threat Coverage — проект, который призван связать разные функции под единой "Threat Centric" методологией (Lockheed Martin Intelligence Driven Defense® aka MITRE Threat-based Security), моделью угроз (MITRE ATT&CK) и предоставить подразделениям информационной безопасности эффективный инструмент для совместной работы над одной задачей — противодействию угрозам.
Почему Atomic Threat Coverage
Работа с существующими [1][2][3][4] репозиторями аналитики выглядит как бесконечное кликание CTRL+C/CTRL+V, ручная адаптация информации под собственные нужды, модель данных, сопоставление с внутренними метриками и так далее.
Мы решили пойти иным путем.
Atomic Threat Coverage это фреймворк для создания вашей собственной базы знаний, импорта аналитики из других проектов (таких как Sigma, Atomic Red Team, а также ваших приватных форков этих проектов с вашей аналитикой) и экспорта этой аналитики в удобные для восприятия человеком статьи в две (на текущий момент) платформы:
- Atlassian Confluence (здесь можно посмотреть автоматически сгенерированную базу знаний)
- В текущий репозиторий — автоматически сгенерированные статьи в вики-формате на языке Markdown
Другими словами, вам не нужно работать с уровнем представления данных вручную, вы работаете только с осмысленными атомарными кусочками информации (такими как Sigma правила), и Atomic Threat Coverage автоматически создаст базу аналитики со всеми сущностями, связанными со всеми важными, действенными метриками, готовую к использованию, распространению, презентации руководству, заказчикам и коллегам.
Как это работает

Все начинается с Sigma правила и заканчивается удобными для восприятия человеком статьями и иной действенной аналитикой. Atomic Threat Coverage парсит Sigma правило, после чего:
- Привязывает Detection Rules к тактикам и техникам ATT&CK, используя
tagsSigma правила - Привязывает Detection Rules к Data Needed, используя
logsourceиdetectionSigma правила - Привязывает Detection Rules к Triggers, (Atomic Red Team тест), используя
tagsSigma правила - Привязывает Detection Rules к Enrichments используя существующие в Detection Rule ссылки
- Привязывает Response Playbooks к тактикам и техникам ATT&CK, используя существующие в Response Playbooks ссылки
- Привязывает Response Actions к Response Playbooks используя существующие в Response Playbooks ссылки
- Привязывает Logging Policies к Data Needed используя существующие в Data Needed ссылки
- Привязывает Detection Rules, Data Needed и Logging Policies к Customers используя ссылки внутри объекта Customer
- Конвертирует все в Confluence и Markdown вики-подобные статьи используя шаблоны jinja (
scripts/templates) - Создает статьи в локальном репозитории и в Confluence (согласно конфигурации в
scripts/config.yml) - Создает индекс в Elasticsearch для визуализации и анализа существующих данных в Kibana
- Создает профили ATT&CK Navigator с визуализацией текущих возможностей детектирования угроз для каждого отдельного клиента (и один общий по всем существующим данным)
- Создает TheHive Case Templates на основе Response Playbooks
- Создает
analytics.csvиpivoting.csvфайлы для простого анализа существующих данных - Создает json файлы дашбордов для Kibana
Под капотом
Типы аналитических данных в репозитории:
├── analytics/
│ ├── generated/
│ │ ├── analytics.csv
│ │ ├── pivoting.csv
│ │ ├── atc_es_index.json
│ │ ├── thehive_templates/
│ │ │ └── RP_0001_phishing_email.json
│ │ └── attack_navigator_profiles/
│ │ │ ├── atc_attack_navigator_profile.json
│ │ │ ├── atc_attack_navigator_profile_CU_0001_TESTCUSTOMER.json
│ │ │ └── atc_attack_navigator_profile_CU_0002_TESTCUSTOMER2.json
│ │ └── visualizations/
│ │ │ └── os_hunting_dashboard.json
│ └── predefined/
│ │ ├── atc-analytics-dashboard.json
│ │ ├── atc-analytics-index-pattern.json
│ │ └── atc-analytics-index-template.json
├── customers/
│ ├── CU_0001_TESTCUSTOMER.yml
│ ├── CU_0002_TESTCUSTOMER2.yml
│ └── customer.yml.template
├── data_needed/
│ ├── DN_0001_4688_windows_process_creation.yml
│ ├── DN_0002_4688_windows_process_creation_with_commandline.yml
│ └── dataneeded.yml.template
├── detection_rules/
│ └── sigma/
├── enrichments/
│ ├── EN_0001_cache_sysmon_event_id_1_info.yml
│ ├── EN_0002_enrich_sysmon_event_id_1_with_parent_info.yaml
│ └── enrichment.yml.template
├── logging_policies/
│ ├── LP_0001_windows_audit_process_creation.yml
│ ├── LP_0002_windows_audit_process_creation_with_commandline.yml
│ └── loggingpolicy_template.yml
├── response_actions/
│ ├── RA_0001_identification_get_original_email.yml
│ ├── RA_0002_identification_extract_observables_from_email.yml
│ └── respose_action.yml.template
├── response_playbooks/
│ ├── RP_0001_phishing_email.yml
│ ├── RP_0002_generic_response_playbook_for_postexploitation_activities.yml
│ └── respose_playbook.yml.template
├── triggering/
│ └── atomic-red-team/
└── visualizations/
├── dashboards/
│ ├── examples/
│ │ └── test_dashboard_document.yml
│ └── os_hunting_dashboard.yml
└── visualizations/
├── examples/
│ └── vert_bar.yml
└── wmi_activity.yml
Detection Rules
Detection Rules — Правила Обнаружения — оригинальные, не модифицированные Sigma правила. По умолчанию Atomic Threat Coverage использует правила из официального репозитория, но вы можете (вам следует) использовать ваши собственные Sigma правила из приватного форка, с внутренней аналитикой, релевантной для вас.
Detection Rule yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть)

Ссылка на Data Needed, Trigger, и статьи в ATT&CK сгенерированы автоматически.
Sigma правило, запросы для Kibana, X-Pack Watcher и запрос GrayLog сгенерированы и добавлены автоматически (этот список может быть расширен и зависит от поддерживаемых Sigma платформах для экспорта правил).
Data Needed
Data Needed yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть)

Эта сущность в первую очередь призвана упростить коммуникацию с SIEM/LM/Data Engineering подразделениями. Она включает в себя следующие данные:
- Детальное описание данных (Platform/Type/Channel/etc) необходимо для вычисления связи с Правилами Обнаружения (Detection Rules)
- Sample — пример лога, описание того как выглядят оригинальные данные, которые необходимо собирать для Обнаружения конкретных угроз и Реагирования на инциденты
- Лист доступных полей необходим для вычисления связи с Правилами Обнаружения (Detection Rules), для генерации сценариев реагирования на инциденты (Response Playbooks), а также для генерации
pivoting.csv
Logging Policies
Logging Policy yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть)
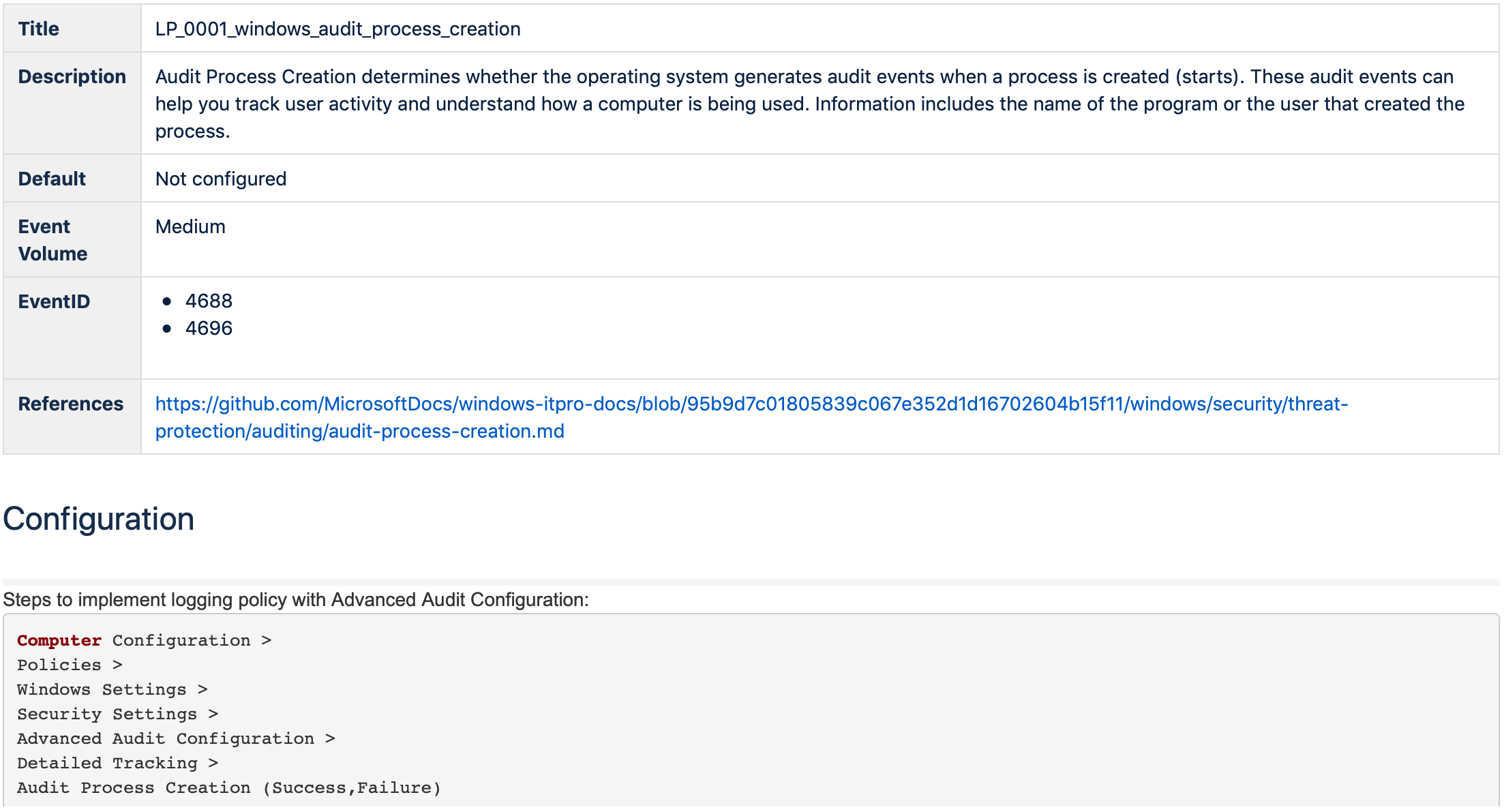
Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть)

Эта сущность призвана упростить коммуникацию с SIEM/LM/Data Engineering подразделениями. Она включает в себя описание конфигурации, которую необходимо реализовать на источнике данных, чтобы собирать данные (Data Needed), необходимые для Обнаружения конкретных угроз и Реагирования на инциденты.
Enrichments
Enrichments yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть)

Эта сущность призвана упростить коммуникацию с SIEM/LM/Data Engineering подразделениями. Она включает в себя:
- Список данных (Data Needed), которые могут быть обогащены
- Описание целей обогащения — новое поле, переименование, новые данные в конкретном поле и так далее
- Пример реализации описываемого обогащения данных (например, с использованием Logstash)
Таким образом можно будет просто и на конкретных примерах объяснить почему вам необходимо какое-то конкретное обогащение данных (посредством связи с Правилами Обнаружения) или какая-то конкретная система для обогащения данных (например, Logstash).
Triggers
Triggers — сценарии имитации атак — оригинальные, не модифицированные Atomic Red Team тесты. По умолчанию Atomic Threat Coverage использует тесты из официального репозитория, но вы можете (вам следует) использовать ваши собственные Atomic Red Team тесты из приватного форка, с внутренней аналитикой, релевантной для вас.
Trigger yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть)

Эта сущность позволяет тестировать возможности по обнаружению конкретных угроз, а также систем/механизмов/технологий обеспечения безопасности. Полное описание можно посмотреть на официальном сайте.
Customers
Customers yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть))

Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть))

Эта сущность позволяет отслеживать какие Logging Policicies настроены, какие данные DataNeeded собираются и какие Detection Rule имплементированы для клиента. Клиент может быть как внутренним ( например удаленный сайт ) так и внешним ( в случае предоставления услуг ). Никаких ограничений на эту сущность нет - это может быть даже конкретный хост.
Эта сущность призвана упростить коммуникацию между отделами SIEM/LM/Data Engineering и сделать прозрачной текущую реализацию для руководства. Сущность используются при генерации
analytics.csv,atc_attack_navigator_profile.json (per customer) и atc_es_index.json.
Response Actions
Response Action yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть)

Эта сущность используется для составления Response Playbooks — планов реагирования на инциденты.
Response Playbooks
Response Playbook yaml (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Confluence (кликните чтобы раскрыть)

Автоматически сгенерированная страница в Markdown (кликните чтобы раскрыть)

Эта сущность используется играет роль плана реагирования на инциденты и служит основной для TheHive Case Templates.
TheHive Case Templates
Atomic Threat Coverage создает TheHive Case Templates построенные с помощью Response Playbooks. Каждый таск в шаблоне кейса является Response Action, связанным с конкретным шагом в IR Lifecycle (по описанию в Response Playbook).
Response Playbook, экспортированный в шаблон кейса TheHive (кликните чтобы раскрыть)

Response Action, экспортированный в таск TheHive (кликните чтобы раскрыть)

Visualizations
Visualization yaml (кликните чтобы раскрыть)

Dashboard yaml (кликните чтобы раскрыть)

Дашборд в Kibana (кликните чтобы раскрыть)

Визуализации включают в себя другие визуализации, Saved Searches и Дашборды, созданные с их помощью. Проще говоря, визуализации представляют собой строительные блоки, из которых можно построить дашборды для разных целей.
На данный момент мы экспортируем только в Kibana, но мы планируем сделать экспорт в другие платформы (в ближайшее время Splunk является нашим приоритетом). Эта сущность может быть описана как Sigma для визуализаций.
Подробная инструкция о том, как ими пользоваться может быть найдена здесь.
atc_es_index.json
Atomic Threat Coverage создает Elasticsearch индекс Со всеми данными и связями для визуализации и аналитики в Kibana. Демо аналитической дашборды ATC построенной на публичных sigma-правилах доступно здесь (user: demo, password: password).
Аналитическая дашборда ATC в Kibana (кликните чтобы раскрыть)

Она призвана помочь ответить на следующие вопросы:
- Какие данные мне нужны чтобы детектировать те или иные угрозы?
- Какие политики логирования я должен настроить для сбора данных, которые мне нужны чтобы детектировать те или иные угрозы?
- Какие данные из тех, что у меня есть, позволяют мне реализовать наиболее критичные правила обнаружения?
- И так далее
В идеале, эти визуализации должны предоставить компаниям возможность связать покрытие угроз с точки зрения детектирования с деньгами. Например:
- Если мы соберем все данные со всех хостов для всех правил детектирования, это будет X событий в секунду (EPS) и нам нужно столько-то ресурсов для их обработки и хранения.
- Если мы будем собирать только данные для высокоприоритетых угроз, это будет Y событий в секунду (EPS) и нам нужно столько-то ресурсов для их обработки и хранения.
- И так далее.
Если у Вас нет ElasticSearch и Kibana под рукой, то вы можете использовать analytics.csv для тех же целей.
atc_attack_navigator_profile.json
Atomic Threat Coverage генерирует ATT&CK Navigator профайл для визуализации текущих возможностей по обнаружению угроз, анализа пробелов, приоритизации разработки, планирования, и так далее. Вам необходимо загрузить этот файл в публичный или (правильнее) приватный сайт ATT&CK Navigator, кликнуть New Tab -> Open Existing Layer -> Upload from local. Вот как выглядит текущий профайл, сгенерированный на основе существующих данных (оригинальные Sigma правила, только Windows):
ATT&CK Navigator профайл для оригинальных правил Sigma (кликните чтобы раскрыть)

analytics.csv
Atomic Threat Coverage генерирует analytics.csv — список данных со всеми зависимостями для простой аналитики посредством фильтров.
Пример фильтра по технике "pass the hash" (кликните чтобы раскрыть)

Этот файл может быть использован для тех же целей что и atc_es_index.json.
pivoting.csv
Atomic Threat Coverage генерирует pivoting.csv — список полей из всех данных которые необходимо собирать для обнаружения конкретной угрозы (Data Needed) с детальным описанием этих данных (категория, платформа, тип, канал, провайдер). Этот файл предназначен для поиска источников данных по конкретному типу данных. Например, в ходе реагирования на инцидент (этап Identification), необходимо выяснить какие источники данных могут предоставить domain name, username, hash и так далее:
Пример фильтра по полю "hash" (кликните чтобы раскрыть)

В то же время pivoting.csv отображает какие поля могу быть найдены только в случае использования конкретных методов обогащения:
Пример фильтра по полю "ParentImage" (кликните чтобы раскрыть)

Цели проекта
- Стимулировать сообщество использовать MITRE ATT&CK фреймворк
- Стимулировать сообщество использовать Sigma правила и Atomic Red Team тесты (больше разработчиков, больше конвертеров правил и больше фреймворков исполнения хорошего качества)
- Евангелизация распространения, обмена Cyber Threat Intelligence
- Автоматизация ручной работы
- Предоставление сообществу фреймворка для улучшения коммуникации с смежными департаментами, сохранения, разработки, анализа и распространения практической, действенной аналитики
Алгоритм использования
Демо контейнер Docker
Вы можете использовать Docker для того, чтобы посмотреть, как ATC работает с данными из открытых источников. Для этого нужно выполнить следующее:
- Клонируйте репозиторий или скачайте архив с ним
- Перейдите в директорию проекта
- Скачайте и обновите репозитории Sigma и Atomic Red Team c помощью git submodules:
git submodule init
git submodule update
git submodule foreach git pull origin master
- Скопируйте
scripts/config.default.ymlвscripts/config.yml - Обновите
scripts/config.yml, указав ссылки на ваш узел Confluence (вам помогут инструкции внутри конфигурационного файла) - Соберите образ с помощью
docker build . -t atc - Запустите контейнер с помощью
docker run -it atc - Введите логин и пароль для Confluence, когда скрипт спросит об этом
После этого Confluence будет заполнен данными и аналитикой, которая будет сгенерирована на вашей стороне (Elasticsearch индекс, csv файлы, TheHive шаблоны, MITRE ATT&CK Navigator профили и т.д.)
Мы пока не рекомендуем Docker для использования в продакшене.
Если вы хотите только посмотреть на конечный результат, вы можете использовать онлайн демо c автоматически сгенерированной базой знаний в Confluence.
Использование в продакшене
- Скопируйте ваши Sigma правила в директорию
detection_rules - Скопируйте ваши Atomic Red Team тесты в директорию
triggering - Добавьте Data Needed в директорию
data_needed(вы можете создать новые используя шаблон) - Добавьте Logging Policies в директорию
logging_policies(вы можете создать новые используя шаблон - Добавьте Enrichments в директорию
enrichments(вы можете создать новые используя шаблон) - Добавьте клиентов в директорию
customers( вы можете создать новые используя шаблон - Добавьте Response Actions в директорию
response_actions(вы можете создать новые используя шаблон) - Добавьте Response Playbooks в директорию
response_playbooks(вы можете создать новые используя шаблон) - Настройте экспорт в Confluence и пути к аналитике используя файл
scripts/config.yml(Вы можете взять файлscripts/config.default.ymlи изменить в нем параметры, исходя из своих нужд) - Исполните команду
makeв корне репозитория - Предоставьте логин и пароль к Confluence, когда скрипт спросит об этом
Если вы хотите частично сгенерировать/обновить аналитику, вы можете посмотреть, какие параметры принимает Makefile или инструкции меню help в scripts/main.py.
Загрузка ATC Analytics Dashboard
Убедитесь что Elasticsearch и Kibana запущены и доступны по сети.
Определите переменные:
ELASTICSEARCH_URL="http://<es ip/domain>:<es port>"
KIBANA_URL="http://<kibana ip/domain>:<kibana port>"
USER=""
PASSWORD=""
Загрузите index template в ElasticSearch:
curl -k --user ${USER}:${PASSWORD} -H "Content-Type: application/json"\
-H "kbn-xsrf: true"\
-XPUT "${ELASTICSEARCH_URL}/_template/atc-analytics"\
-d@analytics/predefined/atc-analytics-index-template.json
Затем загрузите index pattern в Kibana:
curl -k --user ${USER}:${PASSWORD} -H "Content-Type: application/json"\
-H "kbn-xsrf: true"\
-XPOST "${KIBANA_URL}/api/kibana/dashboards/import?force=true"\
-d@analytics/predefined/atc-analytics-index-pattern.json
Затем загрузите дашборд в Kibana:
curl -k --user ${USER}:${PASSWORD} -H "Content-Type: application/json"\
-H "kbn-xsrf: true"\
-XPOST "${KIBANA_URL}/api/kibana/dashboards/import?exclude=index-pattern&force=true"\
-d@analytics/predefined/atc-analytics-dashboard.json
Затем загрузите индекс в Elasticsearch:
curl -k --user ${USER}:${PASSWORD} -H "Content-Type: application/json"\
-XPOST "${ELASTICSEARCH_URL}/atc-analytics/_doc/_bulk?pretty"\
--data-binary @analytics/generated/atc_es_index.json
Можно автоматизировать загрузку индекса, добавив последнюю команду в Makefile в вашем приватном форке. В таком случае каждый раз когда вы будете добавлять новую аналитику, Дашборд будет автоматически обновляться.
Текущая стадия разработки: Alpha
Этот проект на текущий момент находится в стадии Alpha. Он поддерживает не все существующие Sigma правила официального репозитория (на текущий момент покрытие ~80%), также нам предстоит разработать новые сущности (такие как Mitigation Systems). Мы горячо приветствуем конструктивные отзывы, комментарии и предложения по улучшению проекта.
Системные требования
- Unix-подобная ОС или Windows Subsystem for Linux (WSL) (для исполнения
make) - Python 3.7.1
- requests, PyYAML и jinja2 — библиотеки для Python
- Render Markdown — приложение для Confluence (free open source)
FAQ
Отправляется ли куда-либо моя приватная аналитика (Detection Rules, Logging Policies и тд)?
Нет. Только в ваш Confluence портал, в соответствии с конфигурацией в scripts/config.yml. Atomic Threat Coverage не осуществляет никаких других сетевых соединений ни с какими иными удаленными компьютерами, и вы можете это легко проверить.
В таком случае, что вы подразумеваете под "eвангелизацией распространения Threat Intelligence"?
Мы говорим что в случае использование Atomic Threat Coverage вы будете использовать совместимые с сообществом форматы Правил Обнаружения (Detection Rules, Sigma) и сценариев имитации атак (Triggers, Atomic Red Team), и на определенном уровне зрелости у вас (мы надеемся) появится желание поделиться какой-нибудь интересной аналитикой с сообществом. Вам решать.
Как добавить новый Trigger, Detection Rule или иную аналитику в мой приватный форк Atomic Threat Coverage?
Самый простой способ — следовать описанию из параграфа алгоритм использования, добавляя аналитику в предназначенные для них директории.
Продвинутый вариант использования — сконфигурировать ваши приватные форки проектов Sigma и Atomic Red Team как подмодули вешего приватного форка проекта Atomic Threat Coverage.
После этого вам будет необходимо обновить пути к данным в конфигурационном файле scripts/config.yml, таким образом Atomic Threat Coverage начнет использовать вашу собственную аналитику для генерации базы знаний.
Sigma не поддерживает некоторые из моих Правил Обнаружения. Есть ли смысл использовать Atomic Threat Coverage в таком случае?
Определенно. У нас тоже есть набор правил которые не могут быть автоматически сконверированы в запросы SIEM/LM систем посредством Sigma. Мы по прежнему используем Sigma формат для таких правил, помещая неподдерживаемую логику обнаружения в поле "condition". На основе этого поля SIEM/LM команды вручную разрабатывают правила корреляции/поисковые запросы.
ATC это не только автоматическая генерация и документирование поисковых запросов для обнаружения угроз, существует множество других полезных функций для различного рода анализа. Вы не сможете их использовать без Правил Обнаружения в формате Sigma.
Контакты
Авторы
- Даниил Югославский, @yugoslavskiy
- Якоб Вайнзеттл, @mrblacyk
- Матэуш Выдра, @sn0w0tter
- Михаил Аксенов, @AverageS
Благодарности
- Игорю Иванову, @lctrcl за участие в составлении изначального набора данных и правил их взаимосвязи
- Андрею Polar_Letters за логотип проекта
- Проектам Sigma, Atomic Red Team, TheHive и Elastic Common Schema за вдохновение
- MITRE ATT&CK за то что сделали все это возможным
TODO
- Разработать функцию автоматической генерации TheHive Case Templates на основе Response Playbooks
- Разработать спецификацию для кастомных сущностей ATC (таких как Data Needed, Logging Policies и так далее)
- Разработать docker контейнер для проекта
- Создать сущность "Mitigation Systems"
- Создать сущность "Hardening Policies"
- Создать сущность "Visualisation" с визуализациями/дашбордами Kibana, сохраненными в yaml файлах и возможностью их конвертации в curl команды для загрузки в Elasticsearch
Ссылки
[1] MITRE Cyber Analytics Repository
[2] Endgame EQL Analytics Library
[3] Palantir Alerting and Detection Strategy Framework
[4] The ThreatHunting Project
Лицензия
Смотрите файл LICENSE.