| Atomic_Threat_Coverage | ||
| dataneeded | ||
| detectionrules | ||
| enrichments | ||
| images | ||
| loggingpolicies | ||
| scripts | ||
| triggering | ||
| .gitignore | ||
| .gitmodules | ||
| analytics.csv | ||
| LICENSE | ||
| Makefile | ||
| README_PL.md | ||
| README_RU.md | ||
| README.md | ||
🇷🇺 Русская версия | 🇵🇱 Polska wersja
Atomic Threat Coverage
Automatically generated knowledge base of analytics designed to combat threats based on MITRE's ATT&CK.
![]()
Atomic Threat Coverage is tool which allows you to automatically generate knowledge base of analytics, designed to combat threats (based on the MITRE ATT&CK adversary model) from Detection, Response, Mitigation and Simulation perspectives:
- Detection Rules based on Sigma — Generic Signature Format for SIEM Systems
- Data Needed to be collected to produce detection of specific Threat
- Logging Policies need to be configured on data source to be able to collect Data Needed
- Triggers based on Atomic Red Team — detection tests based on MITRE's ATT&CK
- Response Playbooks for reacting on Alerts triggered by specific Threat
- Hardening Policies need to be implemented to mitigate specific Threat
- Mitigation Systems need to be deployed and configured to mitigate specific Threat
Atomic Threat Coverage is highly automatable framework for accumulation, developing, explanation and sharing actionable analytics.
Description
Motivation
There are plenty decent projects which provide analytics (or functionality) of specific focus (Sigma, Atomic Red Team, MITRE CAR). All of them have one weakness — they exist in the vacuum of their area. In reality everything is tightly connected — data for alerts doesn't come from nowhere, and generated alerts don't go nowhere. Each function, i.e. data collection, security systems administration, threat detection, incident response etc are parts of big and comprehensive process, implemented by multiple departments, which demands their close collaboration.
Sometimes problems of one function could be solved by methods of other function in a cheaper, simpler and more efficient way. Most of the tasks couldn't be solved by one function at all. Each function is based on abilities and quality of others. There is no efficient way to detect and respond to threats without proper data collection and enrichment. There is no efficient way to respond to threats without understanding of which technologies/systems/measures could be used to block specific threat. There is no reason to conduct penetration test or Red Team exercise without understanding of abilities of processes, systems and personal to combat cyber threats. All of these require tight collaboration and mutual understanding of multiple departments.
In practice there are difficulties in collaboration due to:
- Absence of common threat model/classification, common terminology and language to describe threats
- Absence common goals understanding
- Absence of simple and straightforward way to explain specific requirements
- Difference in competence level (from both depth and areas perspectives)
That's why we decided to create Atomic Threat Coverage — project which connects different functions on the same Threat Centric methodology (Lockheed Martin Intelligence Driven Defense® aka MITRE Threat-based Security), threat model (MITRE ATT&CK) and provide security teams an efficient tool for collaboration on one main challenge — combating threats.
Why Atomic Threat Coverage
Work with existing [1][2][3][4] analytics/detections repositories looks like endless copy/pasting job, manual adaptation of the information into internal analytics knowledge base format, detections data model, mappings to internal valuable metrics and entities etc.
We decided to make it different.
Atomic Threat Coverage is a framework which allows you to create and maintain your own analytics repository, import analytics from other projects (like Sigma, Atomic Red Team, as well as private forks of these projects with your own analytics) and do export into human-readable wiki-style pages in two (for now) platforms:
- Atlassian Confluence pages (here is the demo of automatically generated knowledge base)
- This repo itself — automatically generated markdown formated wiki-style pages
In other words, you don't have to work on data representation layer manually, you work on meaningful atomic pieces of information (like Sigma rules), and Atomic Threat Coverage will automatically create analytics database with all entities, mapped to all meaningful, actionable metrics, ready to use, ready to share and show to leadership, customers and colleagues.
How it works
Everything starts from Sigma rule and ends up with human-readable wiki-style pages. Atomic Threat Coverage parses it and:
- Maps Detection Rule to ATT&CK Tactic using
tagsfrom Sigma rule - Maps Detection Rule to ATT&CK Technique using
tagsfrom Sigma rule - Maps Detection Rule to Data Needed using
logsourceanddetectionsections from Sigma rule - Maps Detection Rule to Triggers (Atomic Red Team tests) using
tagsfrom Sigma rule - Maps Logging Policies to Data Needed using existing mapping inside Data Needed
- Converts everything into Confluence and Markdown wiki-style pages using jinja templates (
scripts/templates) - Pushes all pages to local repo and Confluence server (according to configuration provided in
scripts/config.py) - Creates
analytics.csvfile for simple analytics of existing data
Under the hood
Data in the repository:
├── analytics.csv
├── dataneeded
│ ├── DN_0001_windows_process_creation_4688.yml
│ ├── DN_0002_windows_process_creation_with_commandline_4688.yml
│ ├── DN_0003_windows_sysmon_process_creation_1.yml
│ ├── DN_0004_windows_account_logon_4624.yml
│ └── dataneeded_template.yml
├── detectionrules
│ └── sigma
├── enrichments
│ ├── EN_0001_cache_sysmon_event_id_1_info.yml
│ ├── EN_0002_enrich_sysmon_event_id_1_with_parent_info.yaml
│ └── EN_0003_enrich_other_sysmon_events_with_event_id_1_data.yml
├── loggingpolicies
│ ├── LP_0001_windows_audit_process_creation.yml
│ ├── LP_0002_windows_audit_process_creation_with_commandline.yml
│ ├── LP_0003_windows_sysmon_process_creation.yml
│ ├── LP_0004_windows_audit_logon.yml
│ └── loggingpolicy_template.yml
└── triggering
└── atomic-red-team
Detection Rules
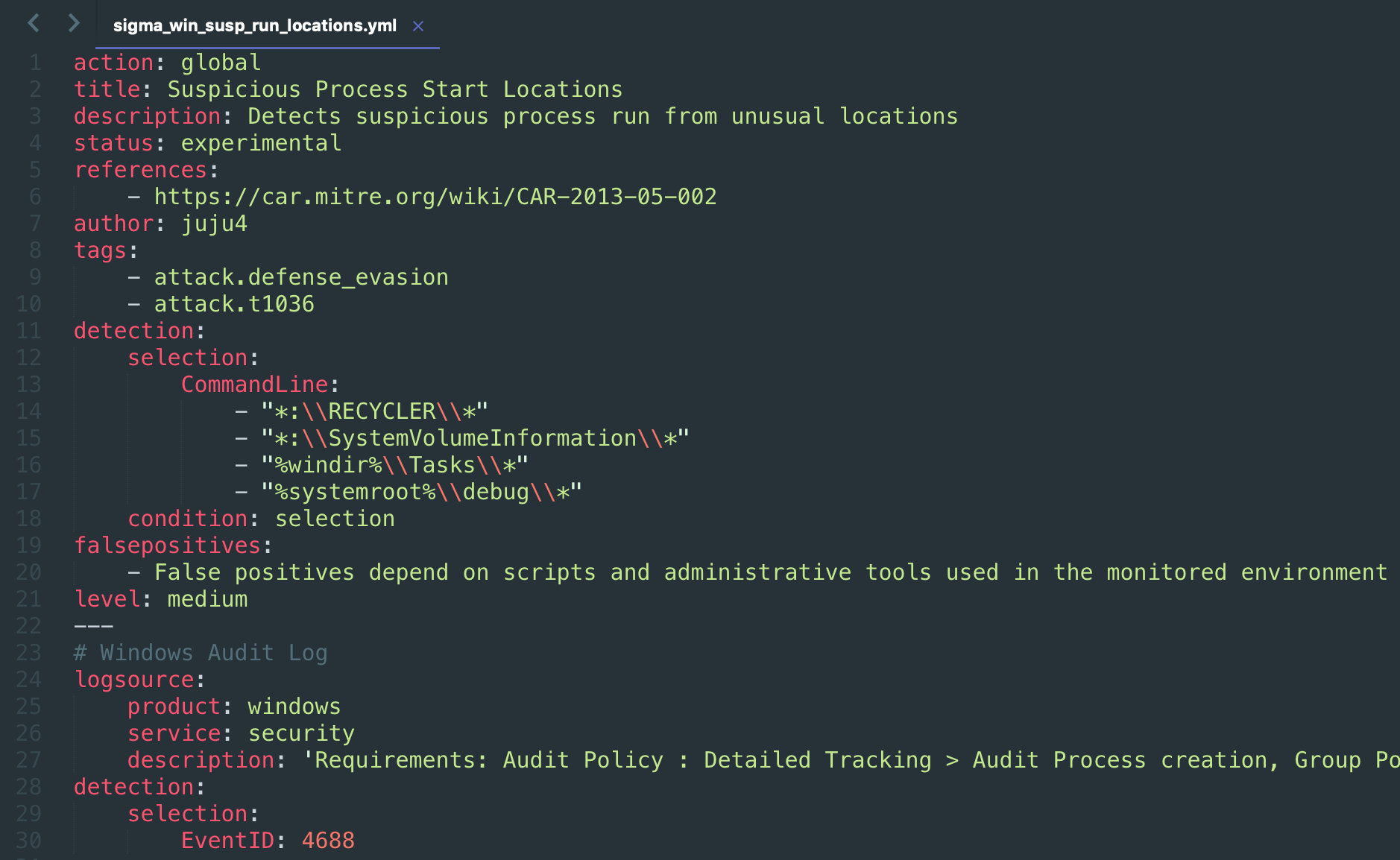
Detection Rules are unmodified Sigma rules. By default Atomic Threat Coverage uses rules from official repository but you can (should) use rules from your own private fork with analytics relevant for you.
Detection Rule yaml (click to expand)
Automatically created confluence page (click to expand)

Automatically created markdown (GitLab) page (click to expand)

Links to Data Needed, Trigger, and articles in ATT&CK are generated automatically. Sigma rule, Kibana query, X-Pack Watcher and GrayLog query generated and added automatically (this list could be expanded and depends on [Sigma Supported Targets](https://github.com/Neo23x0/sigma#supported-targets))
Data Needed
Data Needed yaml (click to expand)

Automatically created confluence page (click to expand)

Automatically created markdown page (click to expand)

This entity expected to simplify communication with SIEM/LM/Data Engineering teams. It includes the next data:
- Sample of the raw log to describe what data they could expect to receive/collect
- Description of data to collect (Platform/Type/Channel/etc) — needed for calculation of mappings to Detection Rules and general description
- List of fields also needed for calculation of mappings to Detection Rules and Response PLaybooks, as well as for
analytics.csvgeneration
Logging Policies
Logging Policy yaml (click to expand)

Automatically created confluence page (click to expand)
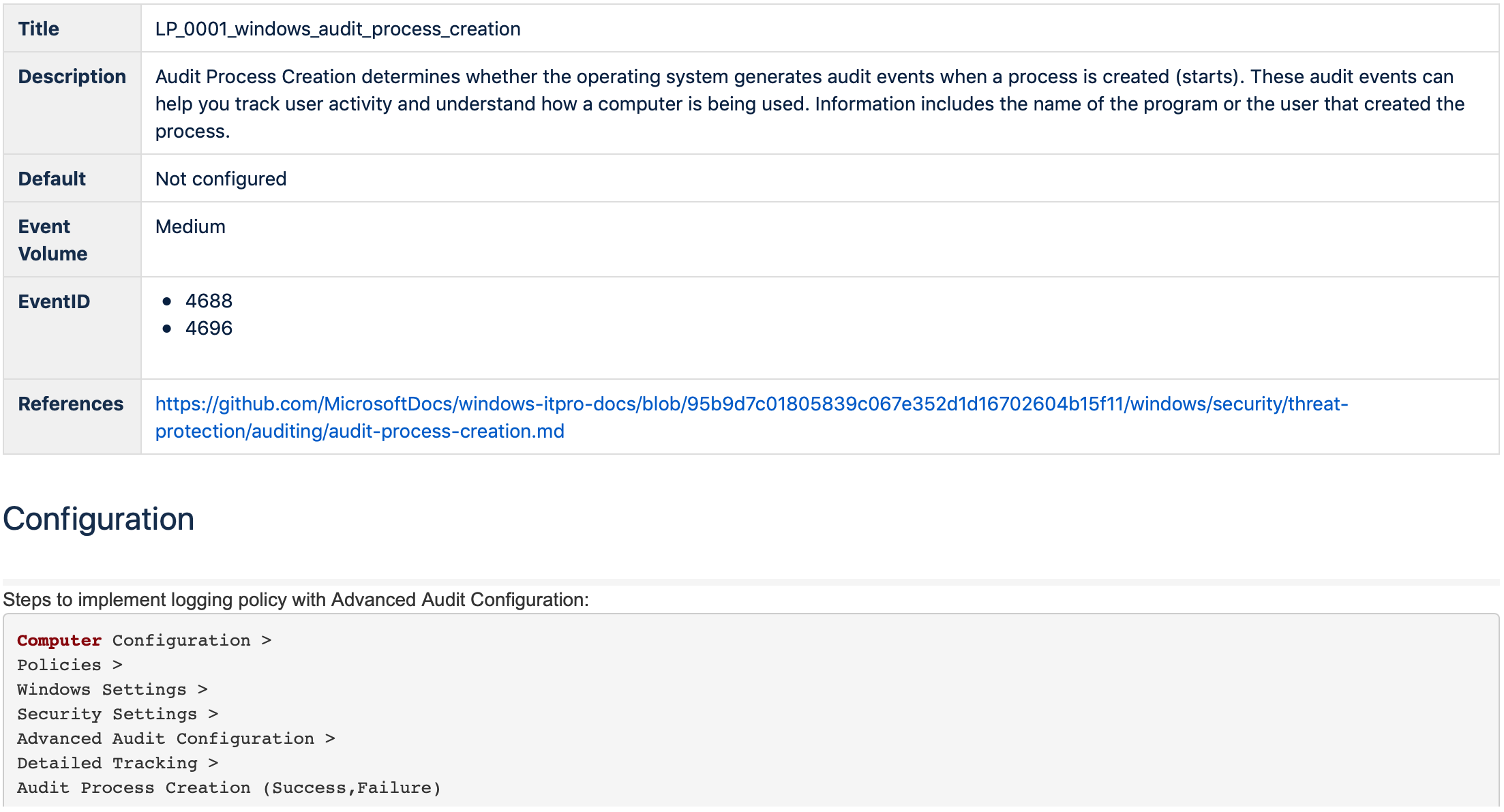
Automatically created markdown page (click to expand)

This entity expected to explain SIEM/LM/Data Engineering teams and IT departments which logging policies have to be configured to have proper Data Needed for Detection and Response to specific Threat. It also explains how exactly this policy can be configured.
Triggers
Triggers are unmodified Atomic Red Team tests. By default Atomic Threat Coverage uses atomics from official repository but you can (should) use atomics from your own private fork with analytics relevant for you.
Triggers yaml (click to expand)

Automatically created confluence page (click to expand)

Automatically created markdown page (click to expand)

This entity needed to test specific technical controls and detections. Detailed description could be found in official [site](https://atomicredteam.io).
analytics.csv
Atomic Threat Coverage generates analytics.csv with list of all data mapped to each other for filtering and simple analytics. This file is suppose to answer these questions:
- In which data sources I can find some specific data type (like domain name, username, hash etc), for example, during triage/incident response (identification stage)
- What data do I need to collect to detect specific threats?
- Which Logging Policies do I need to implement to collect the data I need for detection of specific threats?
- Which Logging Policies I can install everywhere (event volume low/medium) and which only on critical hosts (high/extremely high)?
- Which data provided me most of the high fidelity alerts? (prioritisation of data collection implementation)
- etc
Ideally, this kind of mapping could provide organizations with the ability to connect Threat Coverage from detection perspective to money. Like:
- if we will collect all Data Needed from all hosts for all Detection Rules we have it would be X Events Per Second (EPS) (do calculation for a couple of weeks or so) with these resources for storage/processing (some more or less concrete number)
- if we will collect Data Needed only for high fidelity alerts and only on critical hosts, it will be Y EPS with these resources for storage/processing (again, more or less concrete number)
- etc
Goals
- Stimulate community to use Sigma rule format (so we will have more contributors, more and better converters)
- Stimulate community to use Atomic Red Team tests format (so we will have more contributors and execution frameworks)
- Evangelize threat information sharing
- Automate most of manual work
- Provide information security community framework which will improve communication with other departments, general analytics accumulation, developing and sharing
Workflow
- Add your own custom Sigma rules (if you have any) to
detectionrulesdirectory - Add directory with your own, custom Atomic Red Team detection tests (if you have any) to
triggeringdirectory - Add Data Needed entities related to Sigma rules into
dataneededdirectory (you can create new usingdataneeded/dataneeded_template.yml) - Add Logging Policies related to Data Needed into
loggingpoliciesdirectory (you can create new usingloggingpolicies/loggingpolicy_template.yml) - Configure your export settings using
scripts/config.py - Execute
makein root directory of the repository
Current Status: Proof Of Concept
The project is currently in Proof Of Concept stage and it was developed in a few evenings. It doesn't work for all Sigma rules. We will rewrite most of scripts in a proper way, cover all original Sigma rules and add other entities (like Playbooks). We want to show working example of data processing to discuss it with the community, receive feedback and suggestions.
Requirements
- Unix-like OS or Windows Subsystem for Linux (WSL) (it required to execute
make) - Python 3.7.1
- jinja2 python library
- Render Markdown app for Confluence (free open source)
Authors
- Daniil Yugoslavskiy, @yugoslavskiy
- Jakob Weinzettl, @mrblacyk
- Mateusz Wydra, @sn0w0tter
- Mikhail Aksenov, @AverageS
TODO
- Fix
analytics.csvgeneration - Develop Polish and Russian version of the README
- Rewrite
makeand all bash scripts in python for compatibility with Windows - Rewrite main codebase in a proper way
- Add contribution description
- Create developer guide (how to create custom fields)
- Implement consistent Data Model (fields naming)
- Add the rest of Data Needed for default Sigma rules
- Add the rest of Logging Policies for all Data Needed
- Define new Detection Rule naming scheme (separate Events and Alerts)
- Develop docker container for the tool
- Create MITRE ATT&CK Navigator profile generator per data type
- Create new entity called "Enrichments" which will define how to enrich specific Data Needed
- Implement new entity — "Visualisation" with Kibana visualisations/dashboards stored in yaml files and option to convert them into curl commands for uploading them into Elasticsearch
- Implement "Playbook" entity (based on Detection Rule and Data Needed) with automatic TheHive Case Templates generation (actionable Playbook)
Links
[1] MITRE Cyber Analytics Repository
[2] Endgame EQL Analytics Library
[3] Palantir Alerting and Detection Strategy Framework
[4] The ThreatHunting Project
License
See the LICENSE file.